Твиттер-боты
Все примеры подразумевают использование Python.
Heroku
Регистрация на Heroku
- Регистрируемся на heroku.
- Идём по гайду, устанавливаем утилиты от heroku.
Конфигурация
В heroku конфигурацию принято хранить в окружении.
- Задаём параметры командой:
heroku config:set variable="value". Не забудьте кавычки, особенно если в значении есть пробелы. - В коде получаем доступ к ним с помощью
os.getenv('variable')
Пример бота
git clone https://github.com/strizhechenko/twitterbot_example.git
Содержимое репозитория:
Procfile- объясняет какой командой запускать бота;runtime- какая среда (читай версия python) нужна для запуска бота;requirements.txt- все зависимости бота;bot.py- код бота;morpher.py- вспомогательный модуль для нормализации русскоязычных существительных.
Конфигурация
Я обычно использую в качестве словаря бота не файл или базу, а собственную ленту твиттера. Для этого нужна авторизация под несколькими пользователями:
- самого бота -
user_access_tokenиuser_access_secret - читателя -
strizhechenko_access_tokenstrizhechenko_access_secret
Просмотр конфигурации:
$ heroku config -s
template='%s – это когда тебя любят.'
timeout=30
Регистрация приложения в твиттер
consumer_key и consumer_secret - можно получить зарегистрировав приложение здесь - https://apps.twitter.com/. Это идентификаторы вашего приложения, их лучше никому не знать, в публичный код его зашивать не надо.
Авторизация пользователей
Авторизовать пользователей можно с помощью утилиты в twitterbot_utils:
virtualenv env/
. env/bin/activate
pip install -r requirements.txt
export consumer_key=your_consumer_key
export consumer_secret=your_consumer_secret
python -m twitterbot_utils.TwiAuth
Утилита спросит PIN код, который будет показан в браузере, а затем отдаст: access_token и access_secret. Авторизовать надо и себя и бота, поэтому не забудьте перелогиниться в браузере.
Осталось два парметра template и timeout:
template='%s – это когда тебя любят.'
template - шаблон фразы, в которую будут подставлены существительные, работает как printf почти.
timeout=30
timeout - интервал межд постингом, задаётся в минутах.
Есть ещё две необязательные опции:
tweet_grab = 3
tweets_per_tick = 2
tweet_grab- число твитов, которые подтягиваются из ленты reader’а для поиска существительных.tweets_per_tick- число твитов, которые бот постит за один раз.
Deploy в heroku
Итак мы всё настроили, возможно слегка поправили код bot.py. Закомитьтесь, если что-то меняли:
git add -p
git commit -m "блаблабла"
Меняем origin, репозиторий-пример с гитхаба нам больше не нужен.
git remote remove origin
heroku create yourbotname
git push heroku master
После git push heroku должен обнаружить питоновое приложение и собрать его из requirements.txt:
remote: -----> Python app detected
Закончиться всё должно:
remote: Verifying deploy... done.
Запуск
heroku scale worker=1
Дальше остаётся смотреть логи и чинить если что-то не работает:
heroku logs -t
Перезапуск бота:
heroku scale worker=0
heroku scale worker=1
Ферма
Хостить много твиттер-ботов в Heroku сложно. У меня на момент написания статьи было 10-12. Какие были проблемы?
- Большая часть кода - одинаковая
- Все они состояли из двух ботов, один читает мою ленту, другой преобразует слова и пишет.
- Для каждого отдельные средства управления
- Моя лента - shared-ресурс, но у них не было shared-storage для него.
- Обращения к twitter API тоже shared-ресурс, поэтому они часто упирались в его rate-limit.
- В Heroku нет crontab, приходится пихать в приложение APScheduler, 10-12 ботов хватает чтобы выйти за пределы бесплатных dyno-часов из-за простаивающих приложений.
Я сделал ферму.
Основные идеи
1. Никаких virtualenv
Общее окружение для всех ботов - OpenVZ container.
2. Никаких избыточных вызовов API
Бот-читатель сохраняет свою ленту в Redis. Боты-писатели подписываются на него. В итоге запросы ограничиваются:
- одним
home_timeline()запросом в час от бота-читателя. - одним
update_status()в час на каждого бота-писателя.
3. Одно кольцо чтобы править всеми
Создание, перечисление, получение статистики, уничтожение ботов - это команды. Они стандартные, их не надо каждый раз программировать. Команды вызываются в языке для команд - bash. Я создал утилиту tfctl, по большей части она прозрачная обёртка к python-скрипту и чёрт, отказаться от демонов в пользу crond с вызовами tfctl здорово! Никакого APScheduler, не надо мониторить состояние каждого бота, меньше ресурсов потребляется.
4. С хранилищем меньше повторов
Твиты не повторяются. Это круто.
5. Легче переносимость
Сейчас оно крутится в OpenVZ с 256Мб оперативной памяти. Всё разворачивается с помощью ansible-playbook. У tfctl есть опции export и import, создающие tar-архив, достаточный для восстановления данных, нужных боту (дамп базы redis).
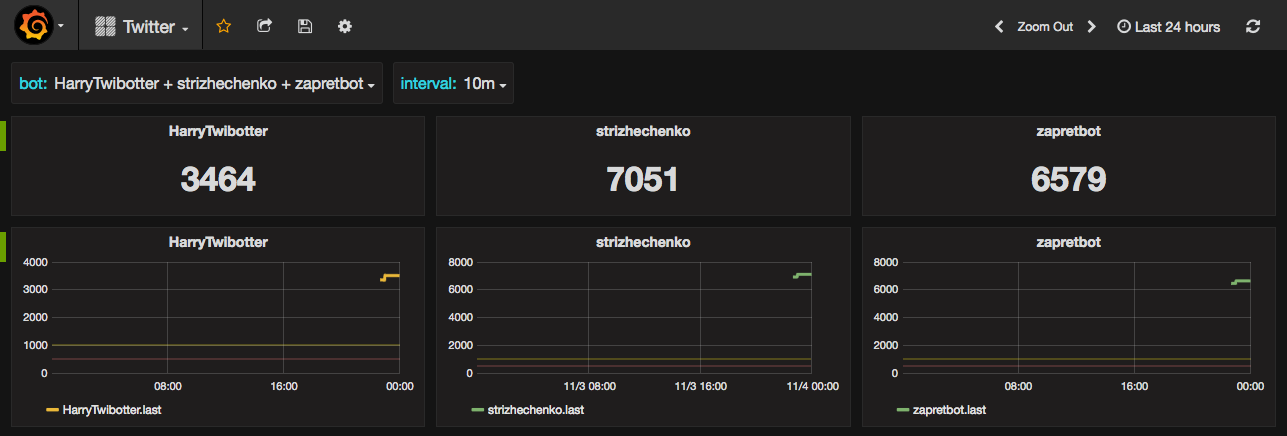
6. Визуализация
Так как всё хранится в одном месте, легче получать статистику и визуализировать её. Так выглядит dashboard для фермы: числа отражают:
- для бота-читателя - число всех сохранённых твитов
- для ботов-писателей - число необработанных твитов
Проблема - я не определился со стратегией хранения кода
Есть несколько вариантов:
| Вариант\Результат | Всё унифицировано | Форкать и бэкпортить легко | Код, которым я горжусь доступен всем | Мой стрёмный код доступен всем | Требуется управление SSH-ключами |
|---|---|---|---|---|---|
| Все боты общедоступны, их список тоже. Можно в виде веток одного репозитория. | + | + | + | + | - |
| Что-то общедоступно (github), что-то закрыто (bitbucket) | - | - | + | - | + |
| Всё закрыто | + | + | - | - | + |