ЧЕРНОВИК. Мониторим продукты Carbon Soft с помощью Grafana + InfluxDB
Эта статья на текущий момент является черновиком. Всё будет оформлено в виде ansible-репозитория, здесь будут только комментарии.
С чего всё началось
Захотелось мне посмотреть на наш основной продукт, биллинг. Красивый ли он, есть ли аналитика, на которую взглянуть приятно аль нет. И что-то не особо. То есть я не хочу сказать, что он беден на аналитику, отчётов там дохрена, отчёт “Для Директора” даже довольно таки красивый (настолько, даже моя ненависть к ущербному неуместному использованию больших букв останется в рамках этих скобочек!). Но остальные же отчёты - сраная скучная текстовая табличка в браузере, которую можно выгрузить в CSV/Excel/DBF (wow!).
И захотелось мне узнать, можно ли любопытному провайдеру прикрутить туда что-то красивое и прекрасное самостоятельно, не формируя сложное техническое задание нашим суппортам, не создавая 50 фич-реквестов и всё такое, не покупая для этого высокоуровневую подписку (SLA4-аутсорсинг или какие там сейчас у нас модные).
Собственно стэк решил использовать привычный мне:
- grafana для отображения графиков
- influxdb как хранилище метрик
- python как инструмент опроса биллинга и отправки метрик в influxdb
- crond как пинатель питоновых скриптов
- collectd - как основной инструмент сбора метрик. Возможно исключит необходимость в crond.
- ansible - как инструмент для поддержания правильного состояния всех конфигураций на нескольких серверах и облегчения повторного развёртывания при необходимости.
Disclaimer: Никаких алертеров или чего-то сверхумного, детекторов аномалий, больших данных и машинного обучения тут не будет. Просто приемлемая визуализация.
Установка
Всё ставится на отдельную машину. Я втыкал в CentOS 6 внутри OpenVZ контейнера. Разворачивал всё с помощью ansible, есть правда косяк в плейбуке, надо вручную одно подтверждение сделать при установке grafana:
файл files/influxdb.conf
reporting-disabled = false
[meta]
dir = "/var/lib/influxdb/meta"
retention-autocreate = true
logging-enabled = true
pprof-enabled = false
lease-duration = "1m0s"
[data]
enabled = true
dir = "/var/lib/influxdb/data"
wal-dir = "/var/lib/influxdb/wal"
wal-logging-enabled = true
[coordinator]
write-timeout = "10s"
max-concurrent-queries = 0
query-timeout = "0"
log-queries-after = "0"
max-select-point = 0
max-select-series = 0
max-select-buckets = 0
[retention]
enabled = true
check-interval = "30m"
[shard-precreation]
enabled = true
check-interval = "10m"
advance-period = "30m"
[monitor]
store-enabled = true # Whether to record statistics internally.
store-database = "_internal" # The destination database for recorded statistics
store-interval = "10s" # The interval at which to record statistics
[admin]
enabled = true
bind-address = ":8083"
https-enabled = false
https-certificate = "/etc/ssl/influxdb.pem"
[http]
enabled = true
bind-address = ":8086"
auth-enabled = false
log-enabled = true
write-tracing = false
pprof-enabled = false
https-enabled = false
https-certificate = "/etc/ssl/influxdb.pem"
max-row-limit = 10000
realm = "InfluxDB"
[subscriber]
enabled = true
[[graphite]]
enabled = false
[[collectd]]
enabled = true
database = "softrouter"
typesdb = "/usr/share/collectd/types.db"
[[opentsdb]]
enabled = false
[[udp]]
enabled = false
[continuous_queries]
log-enabled = true
enabled = true
Файл tasks/influxdb.yml
- hosts: [influxdb]
tasks:
- name: grafana.repo
copy: src=../files/grafana.repo dest=/etc/yum.repos.d/grafana.repo
- name: grafana
yum: name=grafana state=present
- name: crond
yum: name=cronie state=present
- name: grafana
yum: name=cronie state=present
- name: enable crond
service: name=crond enabled=yes state=restarted
- name: enable grafana
service: name=grafana-server enabled=yes state=restarted
- name: collectd (for libs)
yum: name=collectd state=present
- name: influxdb
yum: name=https://dl.influxdata.com/influxdb/releases/influxdb-1.0.2.x86_64.rpm state=present
- name: configure influxdb
copy: src=../files/influxdb.conf dest=/etc/influxdb/influxdb.conf
- name: enable influxdb
service: name=influxdb enabled=yes state=restarted
Поскольку раз уж всё равно экспериментирую в своё свободное время, решил использовать python3.4. Вообще я на нём особо не пишу, так что возможно будет много косяков ниже в статье в примерах кода.
Пробуем юзать
Настраиваем InfluxDB
Открываем 8083 порт виртуалки в первый и в последний раз, чтобы создать базу и настроить политики устаревания и удаления данных. Бигдаты тут как я уже говорил не ожидается, так данные за полгода отлично уместятся на одной машинке без всяких кластеров.
CREATE DATABASE "softrouter";
CREATE RETENTION POLICY "limitations" ON "softrouter" DURATION 180d REPLICATION 1 DEFAULT;
Настраиваем Grafana
Открываем :3000 порт в первый и далеко не последний раз, вводим admin/admin, меню -> data sources -> + add data source.
- name softrouter
- default: +
- type influxdb
- url http://localhost:8086
- database softrouter
Больше особо менять не надо.
Дальше Dashboards -> Create New -> Зелёная херня сбоку -> Add Panel -> Graph. Теперь временно забываем про графики и начинаем думать что бы нам такого пособирать из данных.
Собираем данные
Вообще данные в нашем случае делятся два вида - технические и бизнес.
Поскольку я обкатываю всё на нашем тестовом софтроутере, который служит нам на работе гейтом в инет, то начну с технических.
Технические
Так как у нас под коробкой - Linux, собирать системные данные проще всего с помощью collectd. Там даже думать особо не надо, всё есть в репах.
Настройка: настраивать будем с помощью ansible, поскольку collectd нужно установить на все машины, которые мы хотим отслеживать.
Создадим ansible-playbook для быстрого разворачивания collectd на других машинах и возможности менять конфигурацию в одном месте.
Файл: tasks/collectd.yml:
- hosts: [collectd]
tasks:
- name: install
yum: name=collectd state=present
- name: configure
template: src=../templates/collectd.conf.j2 dest=/etc/collectd.conf
- name: enabled
service: name=collectd enabled=yes state=restarted
Файл: templates/collectd.conf:
FQDNLookup false
Interval 60
LoadPlugin syslog
LoadPlugin conntrack
LoadPlugin cpu
LoadPlugin disk
LoadPlugin interface
LoadPlugin iptables
LoadPlugin irq
LoadPlugin load
LoadPlugin memory
LoadPlugin network
LoadPlugin swap
LoadPlugin tcpconns
LoadPlugin uptime
<Plugin disk>
Disk "/^sda[0-9]$/"
IgnoreSelected false
</Plugin>
<Plugin network>
Server "10.50.140.131"
</Plugin>
Include "/etc/collectd.d"
По красивому IP адрес сервера с collectd надо вынести в переменные группы в файле inventory, но я отложу это на потом.
Запускаем:
ansible-playbook tasks/collectd.yml -l IP-второй-машины
После чего по адресу :8083 можем наблюдать в выводе
show measurements
всё, за чем мы теперь можем наблюдать, у меня:
- conntrack_entropy
- cpu_value
- disk_read
- disk_write
- interface_rx
- interface_tx
- irq_value
- load_longterm
- load_midterm
- load_shortterm
- memory_value
- swap_value
- tcpconns_value
- uptime_value
PPS сетевых карт
В случае с шлюзом и DPI очень важными являются interface_rx и interface_tx. С них и начнём.
Вот пример запроса про входящий pps на eth0 для grafana:
SELECT
non_negative_derivative(mean("value"), 1s)
FROM
"interface_rx"
WHERE
"host" = 'Gate'
AND "type" = 'if_packets'
AND "type_instance" = 'eth0'
AND $timeFilter
GROUP BY
time($interval) fill(null)
IRQ сетевой карты
Можно следить за ростом прерываний на сетевых картах.
У нас используется не очень крутая карта, крутится с одной очередью на 26 прерывании.
SELECT
non_negative_derivative(mean("value"), 1s)
FROM
"irq_value"
WHERE
"host" = 'Gate'
AND "type" = 'irq'
AND "type_instance" = '26'
AND $timeFilter
GROUP BY
time($interval) fill(null)
Единственная проблема которая при такой схеме будет - это отслеживание IRQ сетевых карт. Но в принципе можно отнести это к бизнес-логике, а не техническим данным и захардкодить для каждого хоста (прости господи) или вынести на сторону какого-то своего плагина к collectd.
CPU Usage
Memory Usage
Шаблонизирование в grafana
Вообще много графиков которые находятся рядом имеют очень похожие запросы в основе, меняется как правило одна переменная. Чтобы не менять постоянно в куче мест запросы, можно использовать settings -> templating.
Шаблонизируем uptime load
Сперва добавляем новую переменную, назовём её uptime_kind, type = custom. Values:
load_longterm, load_middleterm, load_shortterm
Multivalue: +
Сохраняем, теперь вверху можно выбирать. Выбираем все. В настройках графика с uptime выбираем from default /^uptime_kind$/ (не забываем указывать host, который кстати тоже можно использовать в шаблонизации).
Теперь идём в general -> repeat panel -> uptime_kind. Ставим span=4, minimal span=4, сохраняем и обновляем страницу. Кстати, переменные можно подставлять куда угодно => темплейтить можно всё что угодно, даже функции.
Шаблонизируем несколько хостов
Так как настраивать и использовать целую дэшбордину только ради одного хоста глупо, попробуем воспользоваться ей для других продуктов.
В templating в grafana добавим переменную Host:
type = query, multivalue отключаем, обновлять только при загрузке dashboard, сам query:
SHOW TAG VALUES FROM "cpu_value" WITH KEY = "host"
Собираем бизнес-данные
Итак, переходим к самому интересному. Если технические данные, описанные выше, можно отслеживать любой системой мониторинга из коробки, то с специфическими для биллинга - придётся немного повозиться. Собственно, чтобы облегчить жизнь возящимся эта статья и пишется. Я попробую сделать кое что новое для меня - оформить всё в виде плагинов для collectd вместо дёрганья питона по крону. Но возможно к питону всё равно придётся обратиться за помощью, так как некоторые данные не так легко просто так взять и собрать.
Биллинг
Число radius событий за час
Число авторизованных абонентов с распределением по NAS-серверам
Данные о работе технической поддержки (заявки в хелпдеске)
Carbon Reductor
NET_RX
Модули фильтрации
В collectd можно также создавать свои плагины. Поэтому всякий custom редуктора туда отлично вписывается. Проблема одна - collectd под рутом скрипты запускать не любит. Так что создаём группу и юзера ему:
groupadd collectd
adduser collectd -s '/bin/bash' -c 'statistic gatherer' -d '/' -g 'collectd' -G 'wheel'
В целом плагины в итоге выглядят довольно шаблонно:
xt_reductor
/etc/collectd.d/reductor.conf
LoadPlugin exec
<Plugin exec>
Exec "collectd" "/usr/lib64/collectd/plugins/xt_reductor.sh"
</Plugin>
/usr/lib64/collectd/plugins/xt_reductor.sh
#!/usr/bin/env bash
PLUGIN_NAME='xt_reductor'
HOSTNAME="${COLLECTD_HOSTNAME:-$(hostname)}"
INTERVAL="${COLLECTD_INTERVAL:-10}"
FILE=/proc/net/${PLUGIN_NAME/xt/ipt}/block_list
replace_regex="s/Registration statement:/gauge-activated /;
s/URL count in database:/gauge-entries_load/;
s/Matched packets:/gauge-matched/;
s/Total packets checked:/gauge-checked/;
s/Elements count:/gauge-db_elements/;
"
while sleep $INTERVAL; do
egrep -v 'Install number|Dont match counter' $FILE | sed -E "$replace_regex" > /tmp/$PLUGIN_NAME
current_date=$(date +%s)
while read var val; do
echo PUTVAL $HOSTNAME/$PLUGIN_NAME/$var $current_date:$val
done < /tmp/$PLUGIN_NAME
rm -f /tmp/$PLUGIN_NAME
done
xt_dnsmatch
/etc/collectd.d/dnsmatch.conf
LoadPlugin exec
<Plugin exec>
Exec "collectd" "/usr/lib64/collectd/plugins/xt_dnsmatch.sh"
</Plugin>
/usr/lib64/collectd/plugins/xt_dnsmatch.sh
#!/usr/bin/env bash
PLUGIN_NAME='xt_dnsmatch'
HOSTNAME="${COLLECTD_HOSTNAME:-$(hostname)}"
INTERVAL="${COLLECTD_INTERVAL:-10}"
FILE=/proc/net/${PLUGIN_NAME/xt/ipt}/block_list
replace_regex="s/Registration statement:/gauge-activated /;
s/URL count in database:/gauge-entries_load/;
s/Matched packets:/gauge-matched/;
s/Total packets checked:/gauge-checked/;
s/Elements count:/gauge-db_elements/;
"
while sleep $INTERVAL; do
egrep -v 'Install number|Dont match counter' $FILE | sed -E "$replace_regex" > /tmp/$PLUGIN_NAME
current_date=$(date +%s)
while read var val; do
echo PUTVAL $HOSTNAME/$PLUGIN_NAME/$var $current_date:$val
done < /tmp/$PLUGIN_NAME
rm -f /tmp/$PLUGIN_NAME
done
xt_snimatch
/etc/collectd.d/dnsmatch.conf
LoadPlugin exec
<Plugin exec>
Exec "collectd" "/usr/lib64/collectd/plugins/xt_snimatch.sh"
</Plugin>
/usr/lib64/collectd/plugins/xt_snimatch.sh
#!/usr/bin/env bash
PLUGIN_NAME='xt_snimatch'
HOSTNAME="${COLLECTD_HOSTNAME:-localhost}"
INTERVAL="${COLLECTD_INTERVAL:-10}"
FILE=/proc/net/${PLUGIN_NAME/xt/ipt}/block_list
replace_regex="s/Registration statement:/gauge-activated /;
s/URL count in database:/gauge-entries_load/;
s/Matched packets:/gauge-matched/;
s/Total packets checked:/gauge-checked/;
s/Elements count:/gauge-db_elements/;
"
while sleep $INTERVAL; do
egrep -v 'Install number|Dont match counter' $FILE | sed -E "$replace_regex" > /tmp/$PLUGIN_NAME
current_date=$(date +%s)
while read var val; do
echo PUTVAL $HOSTNAME/$PLUGIN_NAME/$var $current_date:$val
done < /tmp/$PLUGIN_NAME
rm -f /tmp/$PLUGIN_NAME
done
Настройки графиков в Grafana
Выглядеть это будет как-то так:
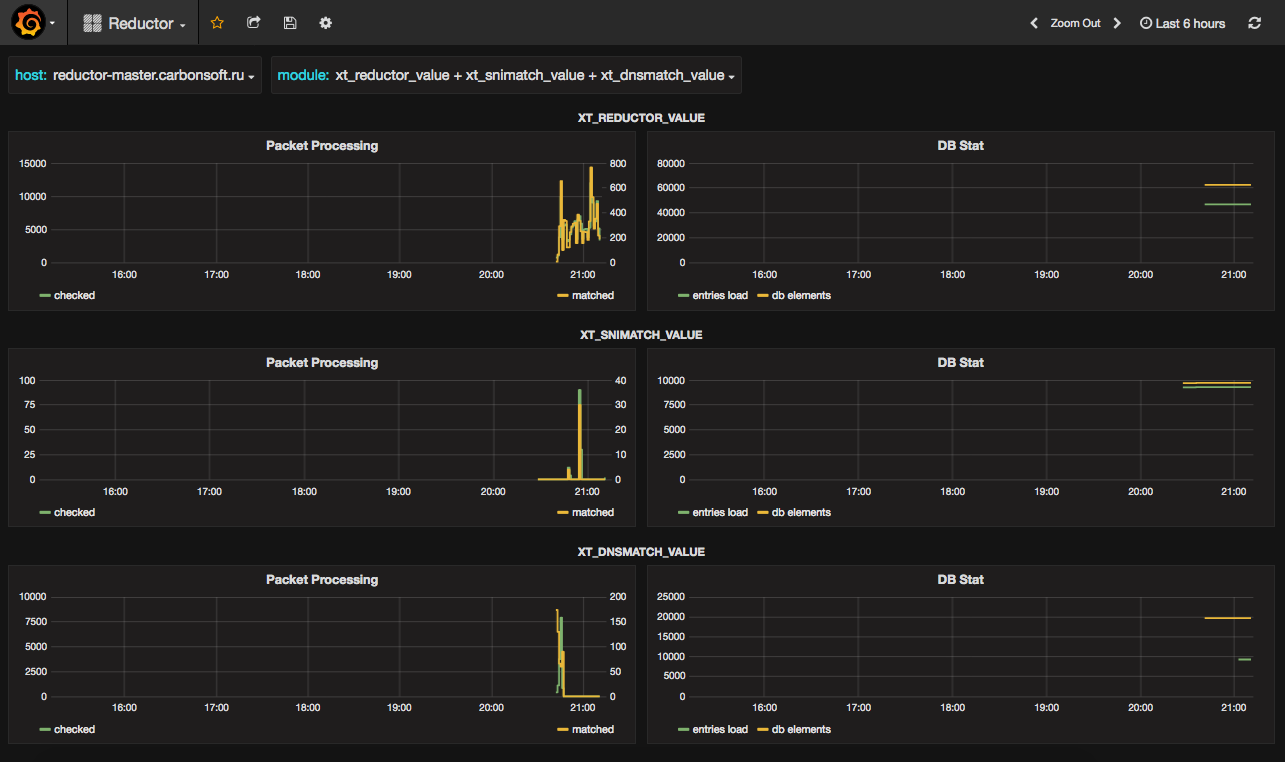
Создадим новую дэшборду, в ней новый ряд, в него в первый график с названием Packet Processing добавим два запроса. Нас интересует их прирост за минуту, так что используем non_negative_derivative(x, 1m).
Проверенные пакеты:
SELECT
non_negative_derivative(last("value"), 1m)
FROM
/^$module$/
WHERE
"host" =~ /^$host$/
AND "type_instance" = 'checked'
AND $timeFilter
GROUP BY
time($interval)
fill(null)
Число срабатываний:
SELECT
non_negative_derivative(last("value"), 1m)
FROM
/^$module$/
WHERE
"host" =~ /^$host$/
AND "type_instance" = 'matched'
AND $timeFilter
GROUP BY
time($interval)
fill(null)
Создадим второй график, DB Stats, в него тоже два запроса:
Число загруженных URL/доменов
SELECT
last("value")
FROM
/^$module$/
WHERE
"host" =~ /^$host$/
AND "type_instance" = 'entries_load'
AND $timeFilter
GROUP BY
time($interval)
fill(null)
и число элементов в базе данных (реально влияющая на производительность величина)
SELECT
last("value")
FROM
/^$module$/
WHERE
"host" =~ /^$host$/
AND "type_instance" = 'db_elements'
AND $timeFilter
GROUP BY
time($interval)
fill(null)