Как релизиться часто, если всё вокруг горит, а требования ужесточаются.
Сразу уточню - всё описанное в этой статье касается опыта работы только в небольших компаниях и командах, занимающихся разработкой ПО.
Терминология
- Release velocity - частота выпуска новых версий
- SLI - Service Level Indicator - какие-либо метрики проекта. Например:
- число тикетов к техподдержке:
- автоматические алерты
- заявки от клиентов
- их сумма
- серьёзные баги
- уход-приход клиентов
- число тикетов к техподдержке:
- SLO - Service Level Objective - цели, то есть значения SLI к которым надо стремиться.
- SLA - Service Level Agreement - соглашения с клиентами по значениям SLI, выход за которые нарушает обязательства, взятые вашей компанией.
О ситуации
Ситуация: живёт себе проект, но мир вокруг него меняется. То, что было приемлемо 5 лет назад кажется “ахаах, ща бы такую халяву”. То, что было рабочим и правильным, в любой момент может оказаться проблемой, которую надо решать. Решение требует времени, которое можно было бы потратить на разработку новых возможностей. Другой взгляд на ситуацию: хочется сохранить возможность хоть как-то релизить софт в обстановке, когда всё вокруг взрывается и ничего с этим не поделать.
Что можно взять из опыта крупных компаний
Мне нравится пирамида потребностей SRE, приведённая в SREBook от Google:
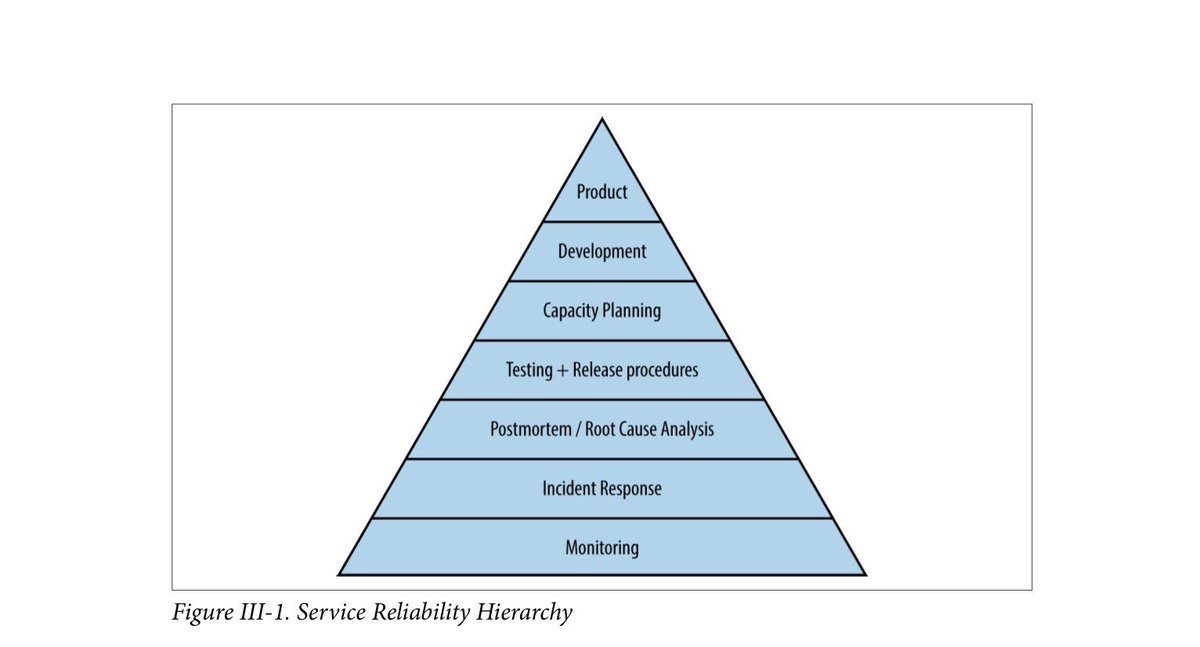
Они хорошо подходят крупной компании с большим штатом. В небольшой команде/стартапе ресурсы ограничены. Выделю несколько вещей, которые подходят и таким командам:
- Мониторинг
- Тестирование
- Постмортемы + их анализ
сэкономленное благодаря ним время перевесит потраченное на налаживание этих процессов. Подробнее:
Возможность быстро выкатить хотфикс
Косяки иногда проходят мимо тестов. С этим надо смириться, полностью от этого избавиться не получится до тех пор, пока наши ресурсы ограничены. Облегчит проблему любой внятный подход к работе с гитом и раскатыванием обновлений: не “пушить в мастер”, мержить фичи в “release”, а не в “master”.
Не факт, что подойдёт, в случае необходимости сертификации на отсутствие недекларированных возможностей.
Обнаружение деградаций
Проводите нагрузочные тестирования, собирайте статистику, храните её, перед релизом и раз в два-три месяца отсматривайте на предмет деградаций. Замеры лучше проводить и на высоких (чтобы покрыть больше кода) и на низких уровнях (чтобы находить более точное место деградации).
Наличие тестов
Нельзя быстро двигаться, когда не уверен. Возможность запустить хотя бы 2-5 минутные smoke-тесты и убедиться что вы не переломали всё в хлам хотфиксом снизит вероятность того, что вы сделаете только хуже. На моей практике самые крупные факапы возникали в процессе торопливого исправления других факапов. Помимо тестов поможет спокойствие, если чувствуете, что уровень стресса повышается - попросите чьей-нибудь помощи. Вам станет спокойнее, плюс ваши действия будут контролировать.
Приоретизируйте!
Любой disaster - критическая задача. Есть такая фраза:
Когда все задачи критические - нет ни одной критической задачи.
Одновременное решение нескольких задач не приводит ни к чему хорошему. Приоритизация каждый раз при выборе следующей задачи и концентрация на ней - лучше что можно сделать. Выбирайте или просите представителей бизнеса помочь выбрать то, с чего нужно начать.
Предотвращайте!
Второе - делайте заглушки в продукте, которые сами решат проблему при возникновении. Делать это лучше при решении временных проблем. В противном случае вы будете всю жизнь заниматься разгребанием рутины и никогда не дойдёте до разработки фич. Если вы откладываете создание этой заглушки и переключаетесь на другую важную критическую проблему - хотя бы создайте себе задачу в jira.
Анализируйте!
Просто писать и читать постмортемы после решения проблемы - недостаточно. Это инструмент приоритизации, с их помощью нужно искать самое проблемное место проекта, крадущее больше всего времени, а не бросаться на всё подряд.