Потери пакетов в Linux, сетевой стек, его тюнинг и мониторинг, netutils-linux
Сетевой стек Linux по умолчанию замечательно работает на десктопах, но на серверах с нагрузкой чуть выше средней и настройками по умолчанию - уже не очень, в основном из-за неравномерного распределения нагрузки на процессор.
Как работает сетевой стек
Коротко
- Материнские платы могут поддерживать одновременную работу нескольких процессоров, у которых может быть несколько ядер, у которых может быть несколько потоков.
- Оперативная память, NUMA. При использовании нескольких процессоров, как правило, у каждого процессора есть “своя” и “чужая” память. Обе они доступны, но доступ в чужую - медленнее. Бывают архитектуры, в которых память не делится между процессорами на свою и чужую. Сочетание ядер процессора и памяти называется NUMA-нодой. Иногда сетевые карты тоже принадлежат к NUMA-ноде.
- Сетевые карты можно поделить по поддержке RSS (аппаратное масштабирование захвата пакетов). Серверные поддерживают, бюджетные и десктопные нет. Зачастую, несмотря на диапазон, указанный в
smp_affinity_listу обработчика прерываний, прерывания обрабатываются только одним ядром (как правило CPU0). Все сетевые карты работают следующим образом:- IRQ (top-half): сетевая карта пишет пакеты в свою внутреннюю память. В оперативной памяти той же NUMA-ноды, к которой привязана сетевая карта, под неё выделен кольцевой буфер. По прерыванию процессора сетевая карта копирует свою память в кольцевой буфер и делает пометку, что у неё есть пакеты, которые надо обработать. Кольцевых буферов может быть несколько и они могут обрабатываться параллельно.
- Softirq (bottom half): сетевой стек периодически проверяет пометки от сетевых карт о необходимости обработать пакеты. Пакеты из кольцевых буферов обрабатываются, проходят, файрволы, наты, сессии, доходят до приложения при необходимости. На этом уровне есть программный аналог аппаратных очередей, который уместен в случае с сетевыми картами с одной очередью.
- Cache locality. Если пакет обрабатывался на определённом CPU и попал в приложение, которое работает там же - это лучший случай, кэши работают максимально эффективно.
Подробнее - путь пакета из кабеля в приложение:
Сразу оговорю неточности: не прописано прохождение L2, который ethernet. С L1 как-то сразу в L3 прыгнул.
- Сетевая карта принимает сигнал.
- Сетевая карта через DMA копирует свою память с пакетом в оперативную память.
- IRQ
- После чего выполняет прерывание (IRQ, то, что видно в /proc/interrupts), которое оповестит ядро о том что пакет пришёл.
- Вызывается функция (IRQ handler), которую зарегистрировал драйвер сетевой карты при иниициализации.
- В контексте обработчика прерывания IRQ выполняется пометка того, что пакеты пора обрабатывать.
- NAPI
napi_schedule()добавляет NAPI poll structure вpoll_listдля текущего ядра и выставляет бит “ПОРА ВЫПОЛНИТЬ SOFTIRQ”! Текущий CPU - CPU, на котором обработалась очередь в которую пришёл пакет.ksoftirqdработающий на данном CPU видит выставленный бит.- Выполняется функция
run_ksoftirqd(), запущенная в бесконечном цикле. __do_softirq()вызывает функцию, прибитую к NET_RX прерыванию, то естьnet_rx_action(). Исполняет её уже не драйвер, а тред ksoftirqd в ядре.
- SoftIRQ
- Контекст softirq - это то, что отображается как %si в выводе
top, счётчики лежат в/proc/softirqs. net_rx_actionв цикле проверяет NAPIpoll_listна наличие NAPI структур.- Проверяется, что
budgetиelapsed timeне израсходованы и softirq не монополизировало ресурсы CPU. - Вызывается poll-функция зарегистрированная драйвером при инициализации, для igb это
igb_poll(). Её задача - извлекать пакеты из кольцевых буферов в оперативной памяти (ethtool -g eth1) и передавать их дальше.
- Контекст softirq - это то, что отображается как %si в выводе
- GRO - Generic Receive Offloading, функция, которая помогает при приёме трафика, но бесполезная и небезопасная при маршрутизации.
- Если включено - выполняется
napi_gro_receive(). При включении пакеты складываются в GRO list. - Если отключено - пакеты попадают непосредственно в
net_receive_skb()
- Если включено - выполняется
net_receive_skb()- место, где вызывается или не вызывается RPS, в зависимости от того, включен он или нет. Если включен:- Пакет кладётся в бэклог с помощью
enqueue_to_backlog(). Предположительно его размер регулируется в/proc/sys/net/core/netdev_max_backlog. Его можно рассматривать как дополнительный промежуточный RX-буфер, который существует для каждого ядра, даже если очередь у драйвера всего одна. - Пакеты распределяются между доступными CPU (указанными в rps_cpus) для дальнейшей обработки.
- NAPI-структура добавляется в
poll_listCPU, на который назначился пакет. В очередь ставится IPI (Inter-processor Interrupt), который вызовет ещё один SoftIRQ. - В процессе работы
ksoftirqdна назначенном CPU происходит то же что и выше, но poll-функция меняяется сigb_poll(), наprocess_backlog(). Последняя разгребает входящую очередь данного CPU.
- Пакет кладётся в бэклог с помощью
- Пакет попадает в
__net_receive_skb_core(или__netif_receive_core()или__netif_receive_skb_core()), во время дальнейшей обработки пакет уже не будет покидать ядро, которое его обрабатывает.__net_receive_skb_core()имеет дело с структуройskbuff. Задача этой функции - доставлять пакеты к taps (PCAP является одним из них).- Пакет закончил прохождение по L2.
- Пакет попадает выше по стеку на L3, для IPv4 это будет
ip_rcv().- Дальше происходят netfilter, iptables и роутинг и всё такое.
- Пакет попадает выше по стеку на L4, в свой UDP/TCP-стек, например в
udp_rcv()udp_rcv()кладёт пакет в очередь на отправку в сокет пользовательского пространства с помощью функцииudp_queue_rcv_skb().- Перед тем как пакет попадёт в очередь к нему применяются BPF (Berkley Packet Filters), которые могут его отбросить.
Альтернативные заметки:
Выводы
Перед главной задачей, выполняется первостепенная задача - подбор аппаратной части, само собой с учётом того, какие задачи лежат на сервере, откуда и сколько приходит и уходит трафика и т.д.
Есть два способа распределить нагрузку по обработке пакетов между ядрами процессора:
- RSS - назначить
smp_affinityдля каждой очереди сетевой карты. - RPS (можно считать его программным аналогом RSS) - назначить
rps_cpusдля каждой очереди сетевой карты. - Комбинирование RSS и RPS. Дополнительный буфер с одной стороны - снижает вероятность потери пакета при пиковой нагрузке, с другой стороны - увеличивает общее времени обработки и может за счёт этого увеличивать вероятность потерь. Для сетевых карт с несколькими очередями и равномерным распределением пакетов перенос пакета с ядра на ядро будет использовать драгоценный budget и снизит эффективность использования кэша процессора.
Как подбирать аппаратное обеспечение
- Процессоры
- Число процессоров:
- Однопроцессорный сервер эффективен, если трафик приходит только на одну сетевую карту, в том числе в её порты, если их несколько.
- Двухпроцессорный сервер эффективен, если есть больше двух источников трафика, с потоком более 2 Гбит/сек и они обрабатываются отдельными сетевыми картами (не портами).
- Число ядер:
- Не нужно больше ядер, чем максимальное суммарное количество очередей всех сетевых карт.
- Hyper-Threading: не помогает, если обработка пакетов - основной вид нагрузки на процессор. Оценивайте процессор по числу ядер, а не потоков.
- Число очередей сетевой карты: карты с одной очередью позволяют распределить нагрузку на обработку пакетов, но не на захват пакетов.
- Частота процессора: чем больше, тем лучше. Лучше начинать от 2.5GHz, 3.5GHz - уже неплохо.
- Объём кэша: чем больше, тем лучше. Отсутствие L3-кэша - показатель того что процессор старый и не поддерживает современные оптимизации.
- Число процессоров:
- Оперативная память: используйте DDR4-память с частотой равной максимальной поддерживаемой и процессором и материнской платой.
- Сетевые карты:
- Размер RX-буферов: чем он больше, тем лучше.
- Максимальное число очередей: чем их больше, тем лучше. Некоторые (mellanox) сетевые карты поддерживают только число очередей равное степени двойки. Если у Вас 6-ядерный процессор - имеет смысл подобрать другую сетевую карту.
- Бракованные сетевые карты - вероятность мала, но иногда случается. Заменяем одну сетевую карту на точно такую же и всё замечательно.
- Драйвер: не рекомендую использовать десктопные карты (обычно D-Link, Realtek).
Мониторинг и тюнинг сетевого стека
Мониторинг можно условно поделить на
- краткосрочный - посмотреть как чувствует себя система прямо сейчас;
- долгосрочный - с алертами, вот это всё.
Заниматься тюнингом без краткосрочного мониторинга равноценно случайным действиям. Я разработал инструменты для такого мониторинга - netutils-linux, они протестированы и работают на версиях python 2.6, 2.7, 3.4, 3.6, 3.7 и, возможно на более новых. Изначально делал для технической поддержки, объяснять каждому такой объёмный материал - долго, сложно. Есть фраза “код - лучшая документация”, а моей целью было “инструменты вместо документации”.
yum -y install python-pip
pip install netutils-linux
При возникновении проблем - сообщайте о них на github, а лучше присылайте pull-request’ы.
Мониторинг
network-top
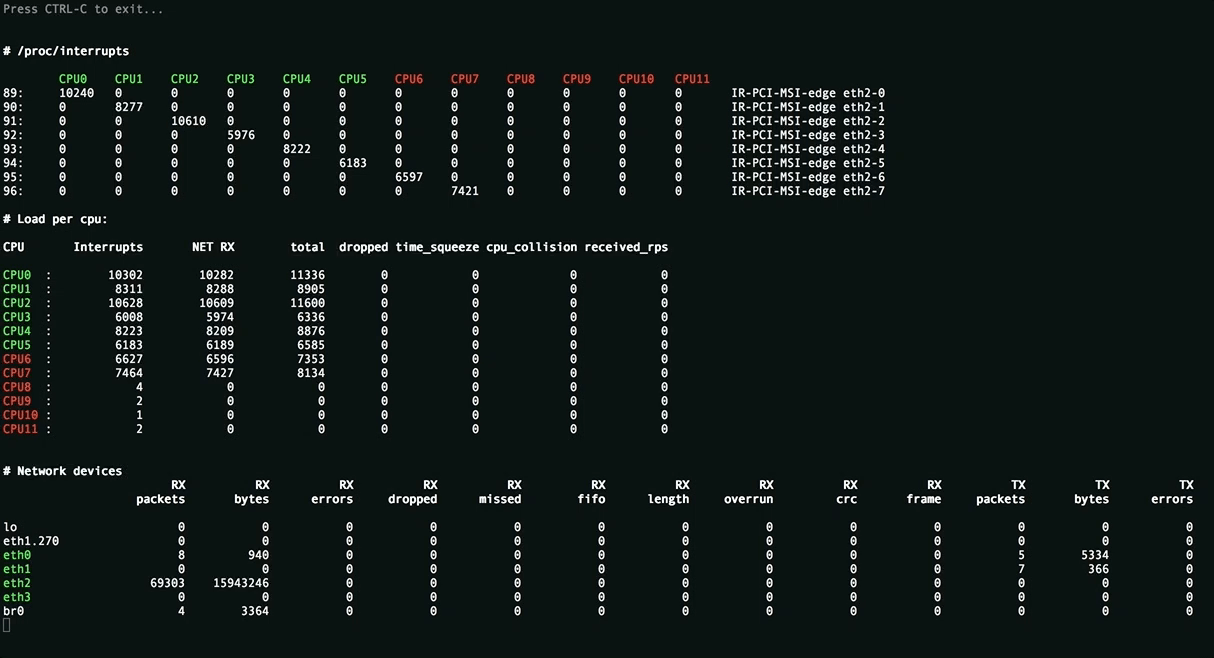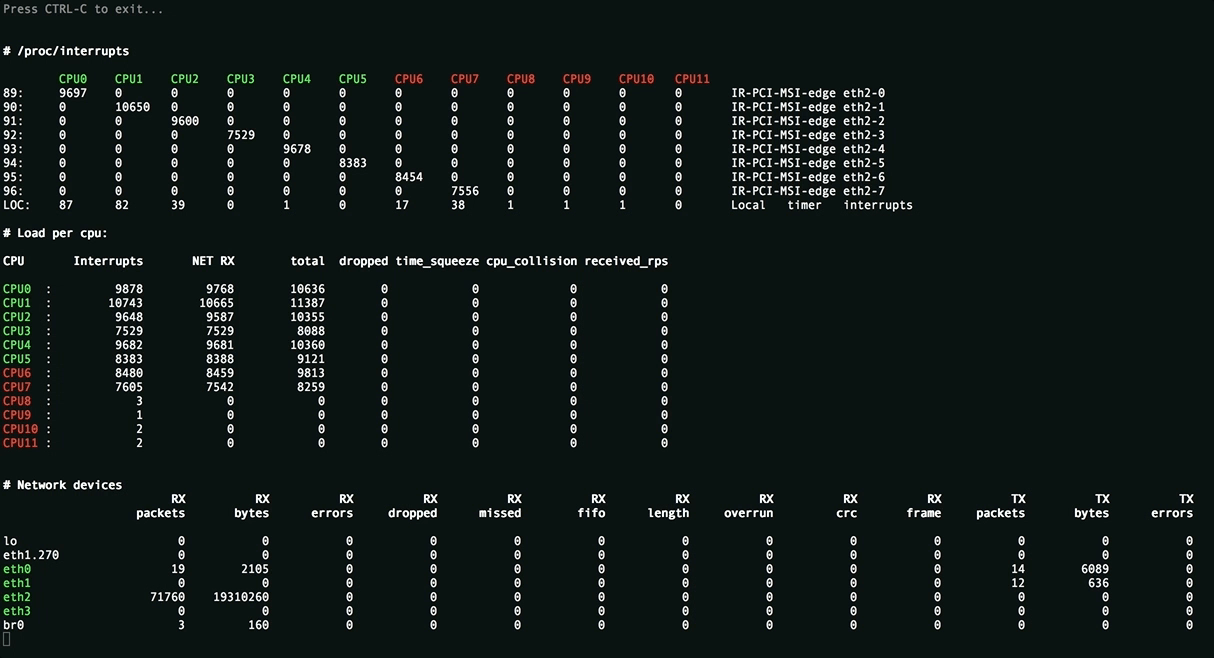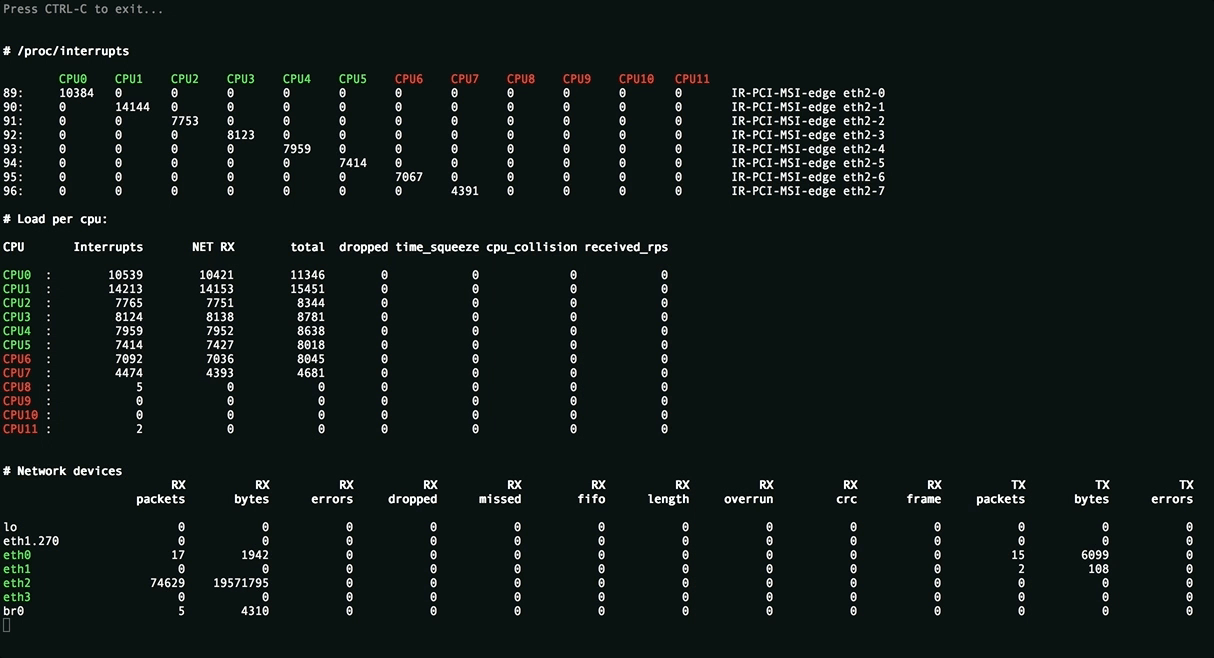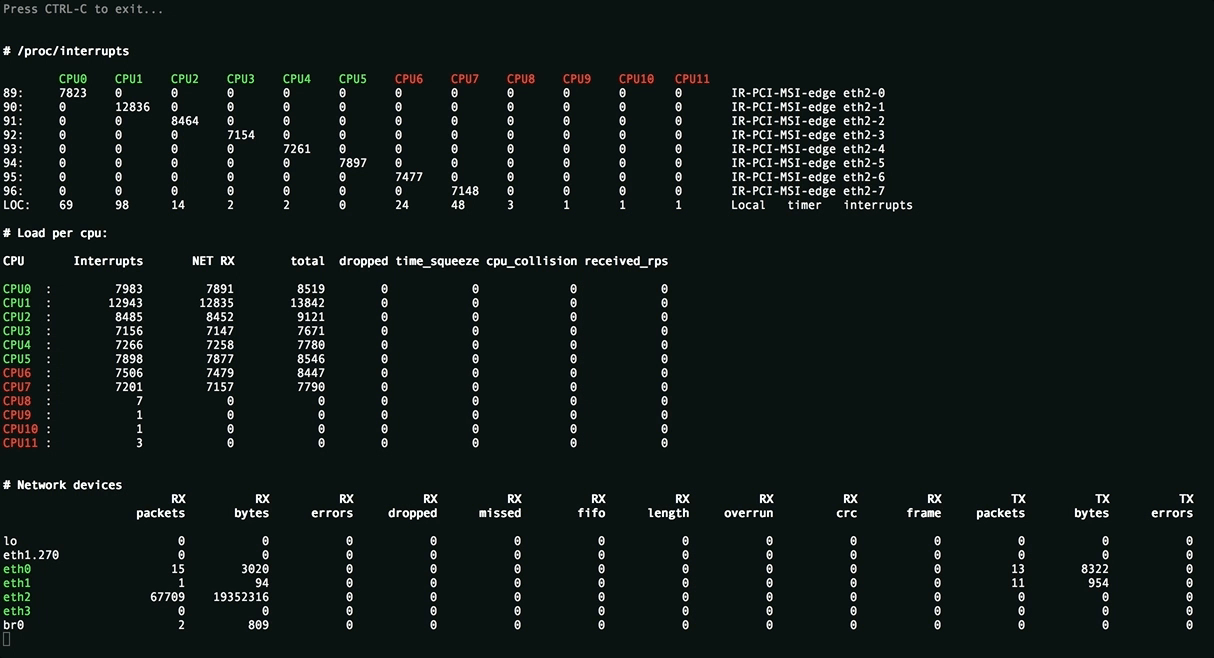
Эта утилита отображает полную картину процесса обработки пакетов. Вы увидите равномерность распределения нагрузки (прерывания, softirqs, число пакетов в секунду на ядро процессора и на сетевой интерфейс) на ресурсы сервера, ошибки обработки пакетов. Аномальные значения счётчиков подсвечиваются красным.
Вверху отображаются источники прерываний, чтобы всё влезало на экран редкие прерывания скрыты. Имена ядер подсвечиваются в зависимости от принадлежности к NUMA-ноде или к процессору.
Посередине находится самое важное - распределение обработки пакетов по CPU:
- Interrupts. Суммарное число прерываний на ядро. Лучше держаться не более 10000 прерываний на 1GHz частоты ядра. В случае с hyperthreading - 5000. Настраивается утилитой
rss-ladder. - NET_RX. Число softirq на приём пакетов. Настраивается утилитой
autorps. - NET_TX. Число softirq на отправку пакетов. Настраивается утилитой
autoxps. - Total. Число обработанных данным ядром пакетов.
- Dropped. Число отброшенных в процессе обработки пакетов. Отбрасывание приводит медленной работе сети, хосты повторно отправляют пакеты, у них задержки, потери, люди жалуются в техподдержку.
- Time squuezed. Число пакетов, которым не хватило времени для обработки и их обработку отложили на следующий виток цикла. Повод задуматься о дополнительном тюнинге.
- CPU Collision. times that two cpus collided trying to get the device queue lock. Ни разу не видел на своей практике.
Внизу находится статистика по сетевым девайсам.
rx-errors- общее число ошибок, обычно суммирует остальные. В какой именно счётчик попадает пакет зависит от драйвера сетевой карты.dropped,fifo,overrun- пакеты, не успевшие обработаться сетевым стекомmissed- пакеты, не успевшие попасть в сетевой стекcrc- прилетают битые пакеты. Часто бывает следствием высокой нагрузки на коммутатор.length- слишком большие пакеты, которые не влезают в MTU на сетевой карте. Лечится его увеличением:ip link set eth1 mtu 1540. Постоянное решение для RHEL-based систем - прописать строчкуMTU=1540в файле конфигурации сетевой карты, например/etc/sysconfig/network-scripts/ifcfg-eth1.
Флаги утилиты
- Задать список интересующих девайсов:
--devices=eth1,eth2,eth3 - Отсеять девайсы регуляркой:
--device-regex='^eth' - Сделать вывод менее подробным, спрятав все специфичные ошибки:
--simple - Убрать данные об отправке пакетов:
--rx-only. - Представление данных об объёме трафика можно менять ключами:
--bits,--bytes,--kbits,--mbits. - Показывать абсолютные значения:
--no-delta-mode
Альтернативные способы получения этой информации:
ip -s -s link show eth2
ethtool -S eth2 | egrep rx_ | grep -v ': 0$' | egrep -v 'packets:|bytes:'
cat /proc/interrupts
cat /proc/softirqs
cat /proc/net/softnet_stat
Потери могут быть не только на Linux-сервере, но и на порту связанного с ним сетевого оборудования. О том, как это посмотреть можно узнать из документации производителя сетевого оборудования.
Стандартный top
Я написал статью о том, как его интерпретировать.
server-info
Если приходится иметь дело с разношёрстными серверами, которые закупались разными людьми, полезно знать какое оборудование у них внутри и насколько оно подходит под текущие нагрузки. Утилита server-info именно для этого и предназначена. У неё два режима:
--show- показать оборудование;--rate- оценить оборудование.
Вывод в YAML. Примеры:
$ server-info --show
cpu:
info:
Architecture: x86_64
BogoMIPS: 6118.0600000000004
Byte Order: Little Endian
CPU MHz: 3059.0300000000002
CPU family: 6
CPU op-mode(s): 32-bit, 64-bit
CPU(s): 2
Core(s) per socket: 2
L1d cache: 32K
L1i cache: 32K
L2 cache: 2048K
Model: 23
Model name: Pentium(R) Dual-Core CPU E6600 @ 3.06GHz
NUMA node(s): 1
NUMA node0 CPU(s): 0,1
On-line CPU(s) list: 0,1
Socket(s): 1
Stepping: 10
Thread(s) per core: 1
Vendor ID: GenuineIntel
Virtualization: VT-x
layout:
'0': '0'
'1': '0'
disk:
sda:
model: ST1000DM003-1ER1
size: 1000204886016
type: HDD
memory:
MemFree: 304516
MemTotal: 3204560
SwapFree: 3341100
SwapTotal: 3342332
net:
eth1:
buffers: null
conf:
ip: ''
vlan: false
driver:
driver: r8169
version: 2.3LK-NAPI
queues:
own:
- eth1
rx: []
rxtx: []
shared: []
tx: []
unknown: []
и оценивать это железо по шкале от 1 до 10:
$ server-info --rate --server
server: 1.76
Вместо --server можно указать --subsystem, --device или вообще ничего, тогда оценка будет вестись по каждому параметру устройства в отдельности.
$ server-info --rate --subsystem
cpu: 4.5
disk: 1.0
memory: 1.0
net: 1.33
system: 1.0
Тюнинг
maximize-cpu-freq
Плавающая частота процессора плохо сказывается для нагруженных сетевых серверов. Если процессор может работать на 3.5GHz - не надо экономить немного ватт ценой потерь пакетов. Утилита включает для cpu_freq_governour режим performance и устанавливает минимальную частоту всех ядер в значение максимально-доступной базовой. Узнать текущие значения можно командой:
$ grep '' /sys/devices/system/cpu/cpu0/cpufreq/scaling_{min,cur,max}_freq
/sys/devices/system/cpu/cpu0/cpufreq/scaling_min_freq:1600000
/sys/devices/system/cpu/cpu0/cpufreq/scaling_cur_freq:1600000
/sys/devices/system/cpu/cpu0/cpufreq/scaling_max_freq:3201000
Помимо плавающей частоты есть ещё одно но, которое может приводить к потерям: режим энергосбережения в UEFI/BIOS. Лучше его выключить, выбрав режим “производительность” (для этого потребуется перезагрузить сервер).
rss-ladder
Утилита автоматически распределяет прерывания “лесенкой” на ядрах локального процессора для сетевых карт с поддержкой нескольких очередей.
Если сетевых карт несколько, лучше выделить для каждой очереди каждой сетевой карты одно физическое ядро, ответственное только за неё. Если ядер не хватает - число очередей можно уменьшить с помощью ethtool, например: ethtool -L eth0 combined 2 или ethtool -L eth0 rx 2 в зависимости от типа очередей.
$ rss-ladder eth0
Distributing interrupts of eth0 (-TxRx):
- eth0: irq 24 eth0-TxRx-0 -> 4
- eth0: irq 25 eth0-TxRx-1 -> 5
- eth0: irq 26 eth0-TxRx-2 -> 6
- eth0: irq 27 eth0-TxRx-3 -> 7
Для RSS по возможности используйте разные реальные ядра, допустим, дано:
- 1 процессор с гипертредингом
- 4 реальных ядра
- 8 виртуальных ядер
- 4 очереди сетевой карты, которые составляют 95% работы сервера
В зависимости от того как расположены ядра и потоки (узнать можно по выводу lscpu -e), использовать 0, 2, 4 и 6 ядра будет эффективнее, чем 0, 1, 2 и 3.
rx-buffers-increase
Увеличивает RX-буфер сетевой карты. Чем больше буфер - тем больше пакетов за один тик сетевая карта сможет скопировать с помощью DMA в кольцевой буфер в RAM который уже будет обрабатываться процессором.
# rx-buffers-increase eth1
run: ethtool -G eth1 rx 2048
# rx-buffers-increase eth1
eth1's RX ring buffer already has fine size.
Для работы после перезагрузки в RHEL-based дистрибутивах (платформа Carbon, CentOS, Fedora итд) укажите в настройках интерфейса, например /etc/sysconfig/network-scripts/ifcfg-eth1, строчку вида:
DEVICE=eth1
ETHTOOL_OPTS="-G ${DEVICE} rx 2048"
autorps
Утилита для распределения нагрузки на сетевых картах с одной очередью. Вычисляет и применяет маску процессоров для RPS, например:
$ autorps eth1
Using mask 'ff' for eth0-rx-0"
Настройка драйверов сетевых карт для работы в FORWARD/Bridge-режимах
Опции General Receive Offload и Large Receive Offload в таких режимах могут приводить к паникам ядра Linux и их лучше отключать либо при компиляции драйвера, либо на ходу, если это поддерживается драйвером:
ethtool -K eth2 gro off
ethtool -K eth2 lro off
Примеры
1. Максимально простой
| Параметр | Значение |
|---|---|
| Число процессоров | 1 |
| Ядер | 4 |
| Число карт | 1 |
| Число очередей | 4 |
| Тип очередей | combined |
| Режим сетевой карты | 1 Гбит/сек |
| Объём входящего трафика | 600 Мбит/сек |
| Объём входящего трафика | 350000 пакетов/сек |
| Максимум прерываний на ядро в секунду | 55000 |
| Объём исходящего трафика | 0 Мбит/сек |
| Потери | 200 пакетов/сек |
| Детали | Все очереди висят на CPU0, остальные ядра простаивают |
Решение: распределяем очереди между ядрами и увеличиваем буфер:
rss-ladder eth0
rx-buffers-increase eth0
На выходе:
| Параметр | Значение |
|---|---|
| Максимум прерываний на ядро в секунду | 15000 |
| Потери | 0 |
| Детали | Нагрузка равномерна |
Пример 2. Чуть сложнее
| Параметр | Значение |
|---|---|
| Число процессоров | 2 |
| Ядер у процессора | 8 |
| Число карт | 2 |
| Число портов у карт | 2 |
| Число очередей | 16 |
| Тип очередей | combined |
| Режим сетевых карт | 10 Гбит/сек |
| Объём входящего трафика | 3 Гбит/сек |
| Объём исходящего трафика | 100 Мбит/сек |
| Детали | Все 4 порта привязаны к одному процессору |
Решение:
Одну из 10 Гбит/сек сетевых карт перемещаем в другой PCI-слот, привязанный к NUMA node1.
Уменьшаем число combined очередей на каждый порт до числа ядер одного физического процессора (временно, нужно делать это при перезагрузке) и распределить прерывания портов. Ядра будут выбраны автоматически, в зависимости от того к какой NUMA-ноде принадлежит сетевая карта. Увеличиваем сетевым картам RX-буферы:
for dev in eth0 eth1 eth2 eth3; do
ethtool -L "$dev" combined 8
rss-ladder "$dev"
rx-buffers-increase "$dev"
done
Необычные примеры
Не всегда всё идёт идеально:
| Проблема | Решение |
|---|---|
| Сетевая карта теряет пакеты при использовании RSS. | 1 RX-очередь для захвата на CPU0, а обработка на остальных ядрах: autorps --cpus 1,2,3,4,5 eth0 |
| У сетевой карты несколько очередей, но 99% пакетов обрабатывается одной очередью | Причина в том, что у 99% трафика одинаковый хэш, такое бывает при использовании QinQ, Vlan, PPPoE и во время DDoS атак. Решений несколько: от DDoS защититься ранним DROP трафика, перенести агрегацию VLAN на другое оборудование, сменить сетевую карту, которая учитывает Vlan при вычислении хэша для RSS, попробовать использовать RPS |
| Сетевые карты intel X710 начала работать без прерываний, вся нагрузка висела на CPU0. | Нормальная работа восстановилась после включения и выключения RPS. Почему началось и закончилось - неизвестно. |
| Некоторые SFP-модули для Intel 82599ES при обновлении драйвера (сборка ixgbe из исходников с sourceforge) “пропадают” из списка сетевых карт и даже флаг unsupported_sfp=1 не помогает. При этом в lspci этот порт отображается, второй аналогичный порт работает, а в dmesg на оба порта одинаковые warning’и. | Не нашлось. |
| Некоторые драйверы сетевых карт работают с числом очередей только равным степени двойки | Замена сетевой карты или процессора. |